「Pythonを使って簡単にデータベースを扱いたい」と思ったことはありませんか?
SQLiteは軽量で手軽に始められるデータベースで、Pythonとの親和性も抜群です。
本記事では、SQLiteを初めて触る方を対象に、テーブル作成やデータの追加・取得・更新・削除といった基本操作をPythonで実践します。
プログラミング初心者でも、この記事を読み進めるだけで、シンプルなデータベースを構築し、活用できるようになります!
SQLiteとは
SQLiteは、軽量で自己完結型のリレーショナルデータベース管理システム(RDBMS)です。他のデータベースシステムとは異なり、サーバーを必要とせず、すべてのデータが単一のファイルに保存される点が特徴です。
| 特徴 | 説明 |
|---|---|
| 軽量で組み込み型 | SQLiteは、サーバーが不要な組み込み型のDBMSです。単一のファイルにすべてのデータを保存するため、簡単に持ち運びができる点が魅力です。 |
| 設定不要で手軽に利用可能 | インストール不要で、すぐに使い始められるため、学習用やプロトタイピングに最適です。 |
| 高い移植性 | SQLiteはどのOSでも動作するため、Windows、Mac、Linux間で簡単にデータベースを共有できます。 |
| 標準SQLのサポート | 基本的なSQL文を使用できるため、他のDBMSへの移行も容易です。 |
| 高速性と信頼性 | メモリ使用量が少なく、データ量が少ない場合でも高速に動作します。また、データの整合性を保証するトランザクションもサポートしています。 |
SQLiteのチュートリアルと詳しいリファレンスについては、下記のSQLite公式サイトに掲載されています。

Pythonでの利用準備
Pythonには、標準ライブラリとしてsqlite3モジュールが含まれています。従って、別途モジュールをインストールすることなく、import だけで利用可能です。
import sqlite3SQLiteで扱えるデータ型
SQLiteはカラムの型を持たない=1つのカラムに異なる型のデータが格納できる
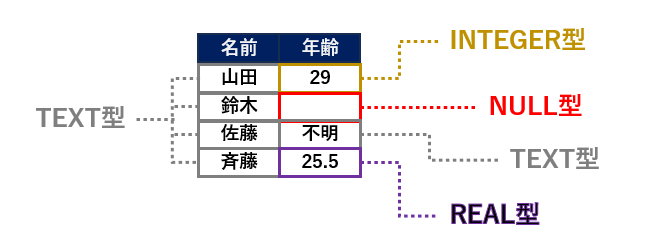
一般的なデータベースではカラムごとにデータ型を指定しますが、SQLiteは格納したデータ1つ1つ(セルごと)に対して、格納したデータに応じて型(ストレージクラス)が決定されます。
下記はSQLiteのセルごとに決定されるストレージクラスの種類です。
| データ型 | 説明 |
|---|---|
| INTEGER | 整数値(1, 2, 3など)。1~8バイトの範囲で保存されます。 |
| REAL | 浮動小数点数値。SQLiteでは8バイトのIEEE浮動小数点数として保存されます。 |
| TEXT | テキストデータ(文字列)。UTF-8、UTF-16BE、またはUTF-16LEの形式で保存されます。 |
| BLOB | バイナリデータ(画像やファイルなど)。そのまま保存されます。 |
| NULL | 値が何もない状態です。 |
ストレージクラスは、個々のセルに格納された値に対して、SQLiteが管理上分類したクラスになります。一般的なデータベースのデータ型とは考え方が異なることに注意してください。
テーブル作成時のデータ型について
SQLiteでテーブルを作成する際、明示的にカラムに対してデータ型を指定することが可能です。
但し、たとえ明示的に指定したとしても、データ登録時に内部でデータ型が決定されることに変わりはありません。
明示的にカラムを指定することの意味は「型変換」です。例えば INTEGER型で指定したカラムに実数のデータを登録した場合、整数に型変換されて格納されます。
データ型には、「INTEGER」「REAL」「TEXT」「BLOB」の4つが指定できます。
DROP TABLE IF EXISTS Test;
CREATE TABLE Test(
NAME TEXT,
AGE INTEGER
);
INSERT INTO Test VALUES('山田',28);
INSERT INTO Test VALUES('鈴木',43.2);
INSERT INTO Test VALUES('佐藤','32');
INSERT INTO Test VALUES('斉藤','満40歳');
INSERT INTO Test VALUES('田中',null);
-- 登録した結果を確認する
select NAME,typeof(NAME),AGE,typeof(AGE) from test;typedef でSQLite内部のデータ型が確認できます。AGEに43.2 をインサートした場合、整数に型変換されて 43 が格納されていますが、内部的には real 型で保持しています。
一方、'満40歳' という文字列を型変換した結果、変換できずに0が格納されましたが、この0は内部的に text 型で保持していることが分かります。
NAME typeof(NAME) AGE typeof(AGE)
山田 text 28 integer
鈴木 text 43 real
佐藤 text 32 integer
斉藤 text 0 text
田中 text null
一般的なデータベースでは、テーブル作成時のデータ型と異なる型のデータを登録するとエラーになりますが、SQLiteではエラーになりません。例えば REAL 型のカラムに 'abc'のような変換不可能なデータを登録した場合、エラーにならず 0 が格納されます。
データベースの作成、接続、切断
データベースの作成
SQLite では、データベースを作成するための専用メソッドはありません。データベースファイルに接続する際、存在しなければ自動的に作成されます。
データベースの接続と切断
データベースへの接続には、sqlite3.connect()メソッドを使用します。この時、データベースが存在しなければ、引数に指定したファイル名で、新しいデータベースファイルが作成されます。
同じ名前のファイルが存在する場合、sqlite3.connect()はそのファイルに接続します。
import sqlite3
conn = sqlite3.connect('example.db')データベースを使い終わったら、接続を切断する必要があります。切断には conn.close()メソッドを使います。
conn.close()with を使ってデータベースに接続すると、 最後に自動でconn.close()メソッドを呼び出してくれます。conn.close()の呼び忘れを防止できるため、この記述が推奨されています。
import sqlite3
with sqlite3.connect('./example.db') as conn:
pass conn.close()の呼び忘れの多くは、エラー発生による異常終了時です。try ~ exception において、例外処理にconn.close()を忘れたり、プログラム終了時にのみconn.close()が記述されている場合に呼び忘れが発生します。
呼び忘れるとデータベースが捕まれた状態になったり、最悪の場合はデータベースが壊れる可能性があるのでwith による接続が推奨されています。
メモリ上にデータベースを作成する
データ量がそれほど多くなく、かつ高速に処理したい場合、もしくはデータベースファイルを残したくない場合、ファイル名の代わりに ':memory:' を指定すると、メモリ上にデータベースを作成できます。
conn = sqlite3.connect(':memory:')conn.close()を呼んだタイミング、又はプログラムが終了したタイミングで、メモリからデータベースファイルが削除されます。
テーブルの作成と削除(CREATE,DROP)
テーブルの作成や削除は、conn.execute()メソッドを使います。引数に Create文や Drop Table 文を記述することで、テーブルの作成や削除が行えます。
CREATE TABLE [ IF NOT EXISTS ] テーブル名(
カラム名1 [データ型] [制約]
カラム名2 [データ型] [制約]
・・・
)
import sqlite3
sql = '''
-- テーブル作成 --
CREATE TABLE IF NOT EXISTS users (
id INTEGER PRIMARY KEY,
name TEXT NOT NULL,
age INTEGER,
email TEXT
)
'''
with sqlite3.connect('./example.db') as conn:
conn.execute(sql)DROP TABLE [ IF EXISTS ] テーブル名
import sqlite3
sql = '''
-- テーブル削除 --
DROP TABLE IF EXISTS users
'''
with sqlite3.connect('./example.db') as conn:
conn.execute(sql)データの更新(INSERT,UPDATE,DELETE)
データの挿入(INSERT INTO)
INSERT INTO テーブル名 [ カラム名1,カラム名2,・・・ ] VALUES(値1,値2,・・・)
import sqlite3
statement = "INSERT INTO users(id,name,age,email) VALUES(1,'山田',31,'yamada@hoge.com')"
with sqlite3.connect('./example.db') as conn:
conn.execute(statement)データの更新(UPDATE文)
UPDATE テーブル名 SET カラム名1=値1,カラム名2=値2,・・・ WHERE 条件式
import sqlite3
statement = "UPDATE users SET AGE = 39 WHERE email = 'yamada@hoge.com'"
with sqlite3.connect('./example.db') as conn:
conn.execute(statement)データの削除(DELETE文)
DELETE FROM テーブル名 WHERE 条件式
import sqlite3
statement = "UPDATE users SET AGE = 39 WHERE email = 'yamada@hoge.com'"
with sqlite3.connect('./example.db') as conn:
conn.execute(statement)トランザクション処理
複数レコードの更新途中でエラーが発生した場合、それまでの更新を無効化するためにトランザクション制御を行うことになります。
SQLiteでは自動コミットが有効になっているため、エラー時にロールバックするだけで構いません。
import sqlite3
with sqlite3.connect('./example.db') as conn:
try:
conn.execute("INSERT INTO users(id, name, age, email) VALUES(103, '澤田', 54, 'sawada@hoge.com')")
conn.execute("INSERT INTO users(id, name, age, email) VALUES(104, '安藤', 49, 'ando@hoge.com')")
except Exception as e:
# エラーが発生した場合はロールバック
conn.rollback()
print(e)もちろん、明示的にトランザクションを開始することも可能です。
この場合、conn.execute("BEGIN TRANSACTION") でトランザクションを開始し、 conn.commit()でコミットします。
import sqlite3
# データベースに接続し、withブロックで自動的にクローズ
with sqlite3.connect('./example.db') as conn:
try:
# データを挿入
conn.execute("BEGIN TRANSACTION") # 明示的なトランザクションの開始
conn.execute("INSERT INTO users(id, name, age, email) VALUES(103, '澤田', 54, 'sawada@hoge.com')")
conn.execute("INSERT INTO users(id, name, age, email) VALUES(104, '安藤', 49, 'ando@hoge.com')")
conn.commit() # 明示的なコミット
except Exception as e:
# エラーが発生した場合はロールバック
conn.rollback()
print(e)
複数のSQLをまとめて実行
複数のSQLをまとめて実行したい場合、cur.executescript()メソッドを使います。
Insert だけでなく、Update、Delete も混在させることができます。
実行途中にエラーが発生した場合、それまでに実行したSQLはコミットされて書き込まれます。必要に応じてトランザクション制御を行ってください。
(エラー発生時にrollback()を実行、または実行するSQLにBEGIN、COMMITを含めるなど)
import sqlite3
statements = '''
--- INSERT,DELETE,UPDATE を混ぜて一度に実行可能 ---
BEGIN;
INSERT INTO users(id, name, age, email) VALUES(1, '山田', 31, 'yamada@hoge.com');
INSERT INTO users(id, name, age, email) VALUES(2, '鈴木', 25, 'suzuki@hoge.com');
INSERT INTO users(id, name, age, email) VALUES(3, '田中', 40, 'tanaka@hoge.com');
UPDATE users SET age = 28 where id = 1;
COMMIT;
'''
with sqlite3.connect('./example.db') as conn:
conn.executescript(statements)conn.executemany()を使うと、SQLのパターン(ひな形)にデータを流し込む方法で、一度に複数のSQLが実行できます。但し、cur.executescript()とは異なり、Insert、Update、 Deleteを混在させることはできません。
import sqlite3
data = [
(11, '山田', 31, 'yamada@hoge.com'),
(12, '鈴木', 25, 'suzuki@hoge.com'),
(13, '田中', 40, 'tanaka@hoge.com'),
]
with sqlite3.connect('./example.db') as conn:
conn.executemany("INSERT INTO users(id, name, age, email) VALUES(?, ?, ?, ?)", data)データの検索(SELECT文)
データの検索は標準的な SELECT 文を使うことができます。
SELECT カラム名1,カラム名2,・・・ FROM テーブル名 [ WHER 条件式 ]
SELECT 文の実行と検索結果の取得方法には コネクションクラスのconn.execute()
conn(コネクションオブジェクト)の execute() を使った検索結果の取得
Insert や Updateと同様に、conn.execute()の引数に Select 文を指定すると、検索結果が戻り値として返されます。conn.execute()は、イテレータであるため、for ループで検索結果を順番に取得できます。
import sqlite3
# データベースに接続
with sqlite3.connect("./example.db") as conn:
# 全データを取得
for row in conn.execute("SELECT * FROM users"):
print(row)(1, '山田', 28, 'yamada@hoge.com')
(2, '鈴木', 25, 'suzuki@hoge.com')
(3, '田中', 40, 'tanaka@hoge.com')
cur(カーソルオブジェクト)の execute() を使った検索結果の取得
カーソルオブジェクトを使うことで、きめ細やかなデータの取得が可能となります。例えば、取得したい件数を指定したり、1つのメソッドで全件をリストに保存することができます。
まず、conn.cursor()メソッドでカーソルオブジェクトを取得し、カーソルオブジェクトの cur.execute()メソッドを使ってSelect 文を実行します。
import sqlite3
# データベースに接続
with sqlite3.connect("./example.db") as conn:
# カーソルオブジェクトを取得
cur = conn.cursor()
# 全データを取得
cur.execute("SELECT * FROM users")
rows = cur.fetchall() # すべての行を取得
# データを表示
for row in rows:
print(row)カーソルオブジェクトを使うと、メソッドを呼び出すごとにカーソル位置が進み、次のメソッド呼び出し時にカーソル位置からレコードが取得できます。
これにより、例えば先頭の2件だけを cur.fetchmeny(2) で取得し、何らかの処理を行った後に、残り全てをcur.fetchall() で取得することが可能となります。
いずれのメソッドにおいても、検索結果を全て取得し終わると None が返されます。
| cur.fetchone() | 現在のカーソル位置から、1行だけ取得し、カーソルを次に進めます。 |
|---|---|
| cur.fetchmeny(size=取得件数) | 現在のカーソル位置から、size 行だけ取得し、カーソルを size 行数だけ次に進めます。 |
| cur.fetchall() | 現在のカーソル位置から、残り全ての検索結果を取得します。 |
conn(コネクションオブジェクト)の execute() でカーソルを使う方法
実は、conn.execute()の戻り値はカーソルオブジェクトです。従って、conn.execute() の戻り値を使って cur.fetchall() を実行することも可能です。
import sqlite3
# データベースに接続
with sqlite3.connect("./example.db") as conn:
cur = conn.execute("SELECT * FROM users")
for row in cur.fetchone():
print(row)インデックスの活用
データベースの検索速度を向上させるためには、インデックスが必要不可欠です。SQLiteでは一般的なデータベースと同様、 CREATE INDEX とDROP INDEXを使います。
CREATE INDEX インデックス名 ON テーブル名(カラム名1,カラム名2,・・・)
import sqlite3
statement = "CREATE INDEX user_email_idx ON users(email)"
with sqlite3.connect('./example.db') as conn:
conn.execute(statement)DROP INDEX インデックス名
import sqlite3
statement = "DROP INDEX user_email_idx"
with sqlite3.connect('./example.db') as conn:
conn.execute(statement)エラー処理とコツ
SQLiteをPythonで扱う際には、エラー処理を適切に行うことが重要です。エラーの原因を特定し、適切な対策を講じることで、アプリケーションの信頼性を向上させることができます。この記事では、SQLite操作時のよくあるエラーとその対処法、さらにトラブルを未然に防ぐコツをご紹介します。
例外処理の実装例
import sqlite3
try:
# データベース接続
with sqlite3.connect("./example.db") as conn:
try:
conn.execute("BEGIN TRANSACTION") # 明示的なトランザクションの開始
conn.execute("INSERT INTO users(id, name, age, email) VALUES(103, '澤田', 54, 'sawada@hoge.com')")
conn.execute("INSERT INTO users(id, name, age, email) VALUES(104, '安藤', 49, 'ando@hoge.com')")
conn.commit() # すべて正常ならコミット
print("トランザクションが正常に完了しました")
except sqlite3.Error as e:
conn.rollback() # 例外発生時にロールバック
print(f"SQLiteエラーが発生しました: {e}")
except sqlite3.Error as e:
print(f"データベース接続エラー: {e}")
finally:
print("処理終了")
SQLインジェクション対策
画面から入力された値を使ってSQL を組み立てて実行する場合、その入力項目に不正なSQL(例えば Delete 文や Drop Table 文など)が含まれていると、それが実行されて大きなトラブルになります。
これを回避するためには、プレースフォルダー(?文字)を使うことが推奨されています。
import sqlite3
# データベースに接続
with sqlite3.connect("./example.db") as conn:
# データをタプルで指定
data = (1000, '田中', 28, 'tanaka@hoge.com')
# SQL文を実行
conn.execute("INSERT INTO users (id, name, age, email) VALUES (?, ?, ?, ?)", data)import sqlite3
data = [
(1001, '山田', 31, 'yamada@hoge.com'),
(1002, '鈴木', 25, 'suzuki@hoge.com'),
(1003, '田中', 40, 'tanaka@hoge.com'),
]
with sqlite3.connect('./example.db') as conn:
conn.executemany("INSERT INTO users(id, name, age, email) VALUES(?, ?, ?, ?)", data)ログの利用
エラーをログファイルに書き出しておくことで、後でエラーの発生タイミングや、エラー内容を確認することができるようになります。下記は最も簡単な(簡易的な)ログ出力方法です。自作ツールの作成など、小規模なプログラムでログを出力する場合は、この方法が便利です。
import sqlite3
import logging
# ログの設定
logging.basicConfig(
filename="./sqlite_errors.log", # ログファイルのパス
level=logging.ERROR, # ログレベル
format="[%(asctime)s] %(levelname)s %(message)s", # フォーマット(タイムスタンプ付き)
datefmt="%Y-%m-%d %H:%M:%S" # タイムスタンプの形式
)
try:
with sqlite3.connect("./example.db") as conn:
cursor = conn.cursor()
cursor.execute("SELECT * FROM nonexistent_table;")
except sqlite3.Error as e:
logging.error(f"SQLiteエラー: {e}")
print("エラーが発生しました。詳細はログを確認してください。")実行した結果、ログファイル(sqlite_errors.log)には次の内容が出力されました。
[2024-11-24 13:42:17] ERROR SQLiteエラー: no such table: nonexistent_table
まとめ
本記事では、SQLiteとPythonを使った基本的なデータベース操作について、テーブルの作成からデータの挿入、更新、削除まで、一通りの操作をシンプルなコードで解説しました。
SQLiteは軽量で設定不要のため、データベース入門に最適です。この基礎を身につければ、小規模なデータ管理やプログラムのデータ保存機能を手軽に実装できます。
次は、応用編でスキーマ情報の取得や最適化テクニックについて解説したいと思います。





コメント