自作プログラムを作成する中で、ファイル名の一覧を取得したい場合がよくあります。
フォルダ内のファイルやサブフォルダを効率的に扱うためには、いくつかの方法がありますが、本記事では、Pythonの標準ライブラリであるos、glob、pathlibを用いる方法について、それぞれの特徴と使い方をサンプルを交えて解説します。
また、walk と glob の特徴を活かした形で、かつコピペで使える便利なサンプルコードも紹介します。
この記事を通じて、ファイル操作のスキルをレベルアップし、日々のプログラミング作業に役立ててください。
ファイル名取得で使える、標準ライブラリ内の3つのモジュール
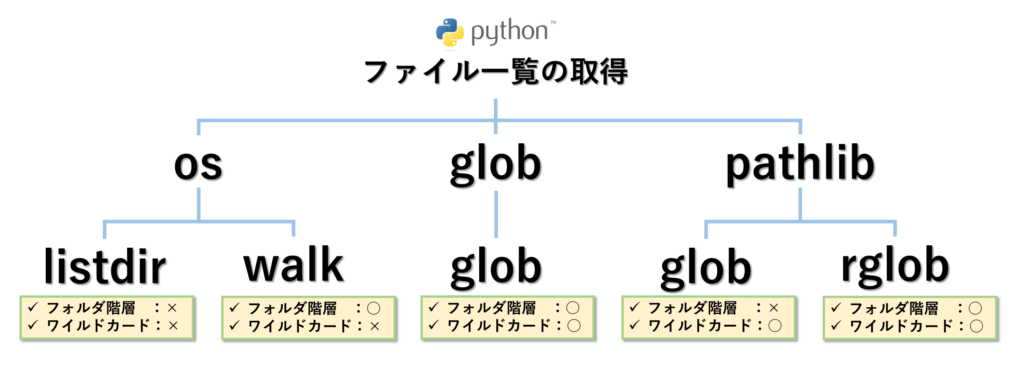
Pythonでは、ファイル一覧の取得に使える標準ライブラリ(os、glob、pathlib)が用意されており、合計5つの関数(os.listdir、os.walk、glob.glob、pathlib.glob、pathlib.glob) が利用できます。
- listdir(os):
指定されたフォルダ内のすべてのファイルとフォルダの名前をシンプルに取得しますが、再帰的な探索はできません。 - walk(os):
指定されたフォルダ内の全てのフォルダとファイルを再帰的に走査し、メモリ効率が良いため大規模なフォルダ構造の探索に適しています。 - glob(glob):
UNIXシェルのワイルドカードを用いたパターンマッチングにより、特定のパターンに一致するファイルを一括で取得しますが、大規模なフォルダ構造の探索には不向きです。 - glob(pathlib):
指定されたディレクトリ内の特定のパターンに一致するファイルを取得します。再帰的な探索は行いません。 - rglob(pathlib):
指定されたディレクトリおよびそのサブディレクトリ内の特定のパターンに一致するファイルを再帰的に取得します。
listdir
指定されたフォルダの中にあるすべてのファイルとフォルダの名前を取得します。
シンプルで使いやすいですが、再帰的にサブフォルダ内のファイルを取得することはできません。
import os
files = os.listdir("/path/to/directory")
for file in files:
print(file)walk
指定されたフォルダ内の全てのフォルダとファイルを再帰的に走査し、戻り値として各フォルダのパス、フォルダ名、ファイル名のタプルを生成します。
/path/to/directory/
├── subdir1/
│ ├── subdir1/
│ └── subsubdir2/
├── subdir2/
│ └── subsubdir3/
├── file1.txt
└── file2.txt
<戻り値の例>
フォルダパス: /path/to/directory
サブフォルダ名: ['subdir1', 'subdir2']
ファイル名: ['file1.txt','file2.txt']
後述する globと異なり、フォルダ階層を走査するごとに結果を返すためメモリ効率が良く、大規模なフォルダ構造を扱うのに便利です。ただしワイルドカードは利用できません。
import os
for dirpath, dirnames, filenames in os.walk("/path/to/directory"):
print(f'Found directory: {dirpath}')
for file_name in filenames:
print(file_name)glob(glob版)
UNIXシェルのワイルドカードを用いたパターンマッチングでファイル名を取得するモジュールです。特定のパターン(例えば、特定の拡張子や名前の一部)に一致するファイルをリスト形式で取得できます。再帰的な検索を行う場合は recursive=True を指定するとともに、ワイルドカードの直前に /**/ を記述する必要があります。
前述の walkとは異なり、全てのフォルダを走査し終わるまで結果が返らないため、大規模なフォルダ構造には向いていません。
import glob
# 拡張子が .txt のファイルを取得(ワイルドカード付き、フォルダ直下のみ)
files = glob.glob("/path/to/directory/*.txt")
for file in files:
print(file)
# 拡張子が .txt のファイルを取得(ワイルドカード付き、ファイルを階層下を含め再帰的に取得)
files_recursive = glob.glob("/path/to/directory/**/*.txt", recursive=True)
for file in files_recursive:
print(file)glob、rglob(pathlib版)
2つのメソッドが用意されており、どちらもワイルドカードの指定は可能ですが、指定したフォルダ直下だけの場合と、フォルダを再帰的に走査する場合では、メソッドを使い分ける必要があります。
from pathlib import Path
# 拡張子が .txt のファイルを取得(フォルダ直下のみ)
for file in Path("/path/to/directory").glob("*.txt"):
print(file)
# 拡張子が .txt のファイルを取得(階層下を含め再帰的に取得)
for file in Path("/path/to/directory").rglob("*.txt"):
print(file)便利な関数サンプル集
ここからは、利用シーンごとにコピペで使える関数のサンプルを紹介します。
指定したフォルダ直下のファイルをワイルドカード指定で取得
get_files()は、第一引数に指定したフォルダにあるファイルの一覧を取得し、リスト形式で返す関数です。
第一引数にフォルダ+ワイルドカードを指定することで、ワイルドカードに一致するファイル一覧が取得できます。
import os
import glob
def get_files(folder,recursive=False,include_hidden=True):
"""
指定されたフォルダ内のファイルを再帰的に取得する関数
:param folder: フォルダのパス
:param recursive: 再帰的に取得するかどうかのフラグ
:param include_hidden: 隠しファイルを含めるかどうかのフラグ
:param wildcard: ワイルドカード(例: *.txt)を指定
:return: ファイルのリスト
"""
if os.path.isdir(folder):
folder = os.path.join(folder,"*")
if recursive:
dir,name = os.path.split(folder)
folder = os.path.join(dir,"**",name)
return glob.glob(folder,recursive=recursive,include_hidden=include_hidden)# 指定したフォルダ直下にあるファイル一覧を取得
files = get_files("C:/")
for file in files:
print(file)
# 指定したフォルダ配下を再帰的に検索し、ファイル一覧を取得
files = get_files("C:/*.png",True)
for file in files:
print(file)指定したフォルダ階層に達するまでファイル名を探索(結果をまとめて返す)
このプログラムは、get_files と同様に指定したフォルダを探索し、ファイル一覧をリストとして返す関数です。
内部で os.walk を使っており、探索する階層に制限を掛ける(指定した階層以下は探索しない)ことができるようになっています。
そのままではワイルドカードは使用できませんが、 取得したファイル名を filesというリスト変数に格納しているため、少し手を加えるだけで任意の条件でフィルタリングすることができると思います。
import os
def limited_get_files(path, max_depth):
"""
指定した階層までのフォルダとファイルを探索する
:param path: 探索を開始するパス
:param max_depth: 探索する最大階層
:return: なし
"""
base_depth = path.count(os.sep)
files = []
for dirpath, dirnames, filenames in os.walk(path):
current_depth = dirpath.count(os.sep) - base_depth
if current_depth == max_depth and max_depth == 0:
# max_depth が 0 の場合、直下のファイルのみ
for file_name in filenames:
files.append(os.path.join(dirpath, file_name))
break
else:
if current_depth >= max_depth:
# 指定した階層を超えた場合はフォルダの探索をスキップ
dirnames[:] = []
continue
# ファイルの一覧を取得
for file_name in filenames:
files.append(os.path.join(dirpath, file_name))
return files# 指定したフォルダ階層に達するまでファイル名を取得する
max_depth = 2 # 探索する最大階層
files = limited_get_files('c:/', max_depth)
for file in files:
print(file)指定したフォルダ階層に達するまでファイル名を探索(結果を少しづつ返す)
このプログラムは、limited_get_files とほぼ同じですが、ジェネレータとして定義されており、1ファイルごと戻り値として返してくるところが異なります。
これにより、大規模なフォルダであっても、メモリ効率よく処理することができます。
import os
def limited_depth_walk(path, max_depth):
"""
指定した階層までのフォルダとファイルを探索する
:param path: 探索を開始するパス
:param max_depth: 探索する最大階層
:yield: ファイルパスを逐次返すジェネレータ
"""
base_depth = path.count(os.sep)
for dirpath, dirnames, filenames in os.walk(path):
current_depth = dirpath.count(os.sep) - base_depth
if current_depth == max_depth and max_depth == 0:
# max_depth が 0 の場合、直下のファイルのみを返す
for file_name in filenames:
yield os.path.join(dirpath, file_name)
break
else:
if current_depth >= max_depth:
# 指定した階層を超えた場合はフォルダの探索をスキップ
dirnames[:] = []
continue
# ファイルパスを逐次返す
for file_name in filenames:
yield os.path.join(dirpath, file_name)ジェネレータ関数であるため、 for ループの in ~ で関数を呼び出して使います。
# 指定したフォルダ階層に達するまでファイル名を取得する
path = 'c:/'
max_depth = 1 # 探索する最大階層
for file_path in limited_depth_walk(path, max_depth):
print(file_path)ファイルの情報を取得する
ファイル名一覧の取得において、ファイルサイズやタイムスタンプでフィルタリングしたい場合がよくあります。
この関数は、引数に指定したファイルパスに対して、ファイルサイズ、作成日時、更新日時、最終アクセス日時をタプルで返します。
import os
import datetime
def get_file_info(file_path, format='%Y/%m/%d %H:%M:%S'):
"""
指定したファイルのサイズおよび各種タイムスタンプを取得する
:param file_path: 情報を取得するファイルのパス
:param format: 日付を表示するフォーマット(デフォルトは 'YYYY/MM/DD HH:MM:SS')
Noneを指定すると、daetime型で返される
:return: ファイルサイズ、作成日時、最終アクセス日時、最終更新日時のタプル
"""
# ファイルサイズを取得
file_size = os.path.getsize(file_path)
# 各種タイムスタンプを取得
create_time = os.path.getctime(file_path)
access_time = os.path.getatime(file_path)
modify_time = os.path.getmtime(file_path)
# タイムスタンプを人間が読みやすい形式に変換
create_time = datetime.datetime.fromtimestamp(create_time)
access_time = datetime.datetime.fromtimestamp(access_time)
modify_time = datetime.datetime.fromtimestamp(modify_time)
# タイムスタンプを指定されたフォーマットで返却
if format is None:
return file_size, create_time, access_time, modify_time
else:
return file_size, create_time.strftime(format), access_time.strftime(format), modify_time.strftime(format)例えば 、Windowsフォルダにある explorer.exe のファイル情報を取得する場合は、次のように記述します。
# タイムスタンプを文字列で受け取りたい場合
file_info = get_file_info("C:/Windows/explorer.exe")
print("**タイムスタンプを文字列で取得**")
print(file_info)
# タイムスタンプを datetime型で受け取りたい場合
file_info = get_file_info("C:/Windows/explorer.exe",None)
print("**タイムスタンプをdatetime型で取得**")
print(file_info)**タイムスタンプを文字列で取得**
(5550800, '2024/10/24 22:06:15', '2024/11/12 23:05:21', '2024/10/24 22:06:15')
**タイムスタンプをdatetime型で取得**
(5550800, datetime.datetime(2024, 10, 24, 22, 6, 15, 820236), datetime.datetime(2024, 11, 12, 23, 5, 21, 558007), datetime.datetime(2024, 10, 24, 22, 6, 15, 945225))
PS P:\MyPythonTool\PyTools\test>
ファイルを比較する
ファイルの差分をコピーしたい時など、単純に2つのファイルが等しいか否かを調べたいときは、 filecmp.cmp が便利です。引数で指定した2つのファイルが等しければ True 、等しくなければ False を返してくれます。
import filecmp
# 2つのファイルを比較し、等しければ True 等しくなければ False を返す
res = filecmp.cmp('d:/file1.bin', 'd:/file2.bin', shallow=True)shallow=True にすると、ファイルのメタデータ(最終更新日、サイズ、アクセス権など) に基づいて比較が行われます。shallow=False にすることで、時間は掛かりますが、ファイルの内容を比較してくれます。
まとめ
この記事では、Pythonでファイル名の一覧を取得するための便利なサンプルコードを紹介しました。特に、os、globのライブラリを使った5つの標準関数(os.listdir、os.walk、glob.glob、pathlib.glob、pathlib.glob) について、それぞれの特徴と使い方を解説しました。
また、利用シーンごとにコピペで使える関数のサンプルとして、指定したフォルダ直下や階層ごとにファイルを取得する方法、ジェネレータを使用してメモリ効率よく処理する方法、ファイル情報の取得(ファイルサイズ、各種タイムスタンプ)関数も紹介しました。
これらのサンプルコードを活用することで、Pythonでのファイル操作がより効率的に行えるようになります。皆さんの日々のプログラミングや業務の中で、ぜひ参考にしてください。

コメント